

Apr 26, 2024 10:30:38 AM
Data protection and privacy have become focal points of discussion as individuals grow increasingly mindful and worried about the lifespan of their personal data across various services. Regulated by legislation such as the European Union's General Data Protection Regulation (GDPR), this field is garnering substantial attention.
This blog post takes a deep dive into data protection from a data warehouse modeling perspective. More precisely, we'll explore modeling principles that enable compliance with regulatory requirements, such as the right to data access or erasure, all while preserving the data model's structural integrity. We'll also shed light on data vault modeling examples in this context.
Separating Sensitive and Non-Sensitive Information
Maintaining sensitive data requires meticulousness and a disciplined approach to data modeling and storage, a task that grows increasingly challenging with the expansion and complexity of a data warehouse. Sensitive data must be both logically and physically isolated from non-sensitive data to facilitate the scalable execution of data protection requests, ideally via automated processes.
Given the potentially high volume of requests, it's often unsustainable to manually process every customer request for personal data deletion. Automating this requires a deep understanding of which parts of the data are personally identifiable and where they're stored. A clear segregation of sensitive and non-sensitive data also makes governing data access and usage more manageable.
Keeping sensitive data in your data warehouse orderly necessitates a cautious modeling process, where data sensitivity is evaluated whenever new data sources are incorporated into the warehouse. Sensitive fields must be identified and modeled according to set principles. This task can become challenging due to the potency of joining different pieces of information. For instance, a date of birth might be anonymous within a large population, but it could become easily identifiable when linked to a sparsely populated postal code area.
While sensitive information often pertains to personally identifiable information (PII) in this context, similar principles can be applied to other types of sensitive data as well.

Managing Sensitive Business Keys
Linked to the distinction between sensitive and non-sensitive data, sensitive business keys are a crucial topic to address. These keys serve as the connecting threads within the data model in a data warehouse, and can themselves be sensitive. For example, person keys such as social security numbers or employee or customer numbers are identifiable pieces of data.
To enable selective erasure of sensitive information while maintaining the data model's integrity and keeping the non-sensitive part of the data usable, sensitive keys or keys derived from them should not be used as entity keys in the data warehouse. This poses a challenge in data vault implementations, which usually rely on hashed business keys as entity keys. Despite their uniformity and the fact that hash keys don't require any lookups when loading the entities, hashed business keys can't be retained in a data erasure as someone could easily identify them by recalculating the hashes, given they have a list of natural business keys. As such, random surrogate keys and key lookups are also required in the data vault for linking sensitive entities.
Business keys play a vital role in the modeling process where sensitive and non-sensitive information are separated. All data must be interconnected to facilitate effective data analysis and end-use. These linkages are also crucial for managing data protection request-related operations. Under GDPR, it should be possible to seamlessly sever the link between sensitive and non-sensitive information, erase the sensitive parts, or merge everything together and generate an extract of all stored customer data. Additionally, the customer may send a request to modify certain details after reviewing their data.
These data protection rights pose significant demands on the data model and the quality of customer master data, as customer data is often generated and sourced from multiple operative systems. Without a clear understanding of which records are linked to a data protection request, for example, the identifier of a particular customer across different systems, fulfilling the request can be a daunting task.
Example: Sensitive Data Vault
Imagine a scenario where you have datasets that consist of person master data and order transactions referencing individuals. In the diagram below, the data is separated into two distinct zones in the raw data vault: sensitive and non-sensitive.
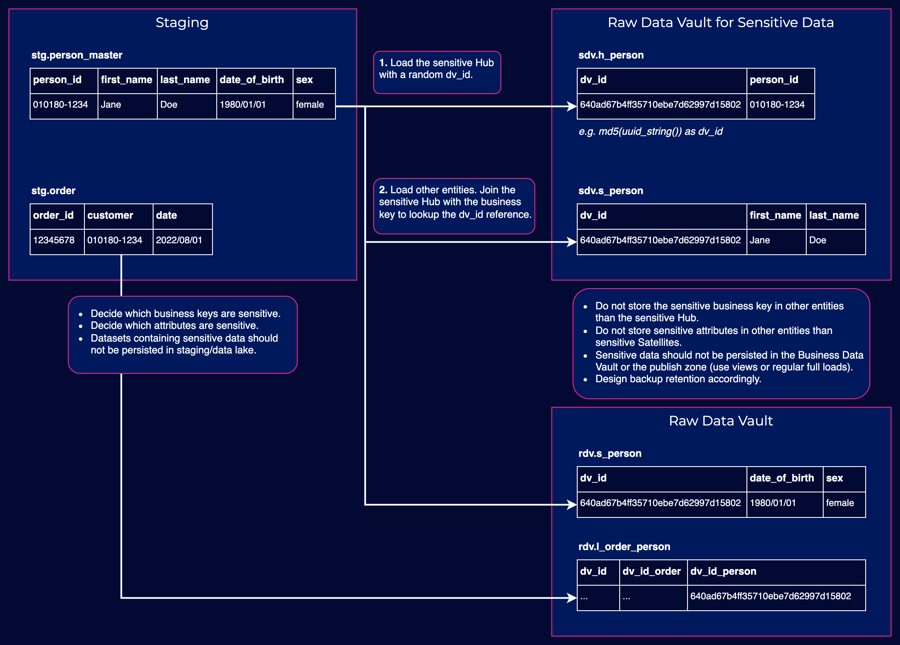
For added security, the person key is randomized. Although this results in having to use lookups in the loads, it also permits its retention even if the person key and connected sensitive attributes must be removed. It's important to note that you should always load the sensitive hub first because related entity loads now rely on it.
Data Erasure Made Simple
Thanks to the deliberate segregation of sensitive and non-sensitive zones, it's much easier to automate data erasure operations. From the sensitive zone, you can remove all related items, except for the randomized key, while leaving the non-sensitive zone untouched. This approach also ensures that the rest of the data vault model remains intact, since all links and satellites pointing to the sensitive hub use the randomized key.

Bear in mind that for data erasure to be effective, personal data should only be stored in the sensitive raw data vault zone. Techniques like using views and/or regular full loads to overwrite tables on downstream zones (like the business data vault or publish zone) ensure that sensitive data is also deleted from these areas. Similarly, sensitive data shouldn't be stored upstream (such as in staging or data lake) unless there are similar processes implemented there.
It's important to remember that this discussion is centered on the perspective of data warehousing. Naturally, data protection requests, like erasures, must be primarily managed in operative systems where the data originates, making the process more complex in real life. For instance, a signal from an operative system might trigger a data erasure in the data warehouse, but then we need to consider that the erased identity might still appear in source data coming from other systems.
Data Extraction: Providing Individuals Access to Their Data
A well-designed data vault model lays a solid foundation for providing automated data extracts for individuals exercising their right to access their data. Ideally, all data connected to a person should be linked to the person hub via links and satellites. A data warehouse could be the best place to create such an extract, as data warehouses usually hold comprehensive data from various source systems and operate on platforms technically capable of running such queries.
In practice, a solution for data extraction could involve views that join and flatten the data from the data vault model, as shown in the diagram below.
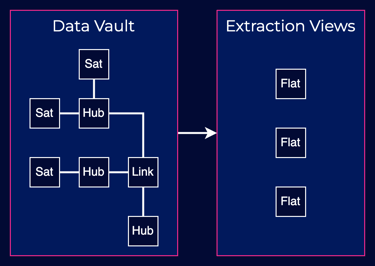
An automated process could then use these views to create files containing all the data associated with individuals. Of course, there will be additional complexity in real-life situations when designing and maintaining these views, as concepts tend to be interlinked in multiple ways. This is where expert knowledge of the subject matter often comes into play.
Conclusions
Navigating the intricate labyrinth of data protection and privacy is a complex yet indispensable task in today's digital world. The issues revolve around ensuring we comply with regulations, like the General Data Protection Regulation (GDPR), while also maintaining an efficient and functional data model. A critical aspect of this lies in successfully splitting sensitive and non-sensitive information, helping to facilitate the scalability and automation of data protection requests, such as erasure or data access.
Our examples demonstrated the use of randomized person keys in the data modeling process. This method allows for the selective deletion of sensitive information without disturbing the overall structure of the data warehouse or impairing the usability of non-sensitive data. The introduction of these randomized keys necessitates extra processing steps, but the advantages in terms of data protection and scalability clearly outweigh the initial investment in terms of time and effort.
Moreover, the proper separation and management of sensitive and non-sensitive data zones make data erasure operations more effective. By solely persisting personal data in the sensitive zone of the raw data vault, and implementing regular refresh processes in downstream zones, we ensure sensitive data gets completely erased when necessary.
In terms of providing individuals access to their data, a well-designed data model is instrumental. It allows for automated data extraction processes to generate comprehensive and relevant data extracts.
However, it is crucial to remember that these processes and operations are part of a much larger, interconnected ecosystem, extending beyond the realms of data warehousing and into the operative systems where data originates. This introduces another level of complexity that must be taken into account to ensure complete and effective compliance with data protection regulations.
As the need for data protection continues to grow, a flexible, efficient, and secure approach to data modeling will remain a paramount concern for all organizations.



