Data Vault Automation
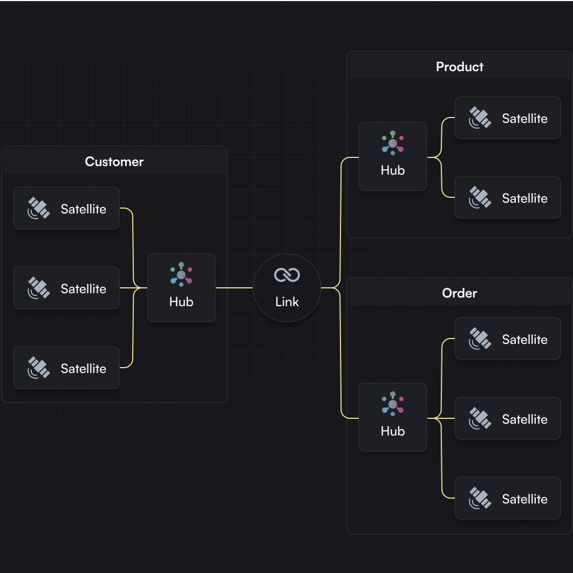
Accelerate resilient data warehouse development with automated Data Vault modeling and standardized transformations—delivering the agility, traceability, and scalability Data Vault methodology was designed for. Agile Data Engine was developed with input from experienced Data Vault professionals and is fully aligned with Data Vault 2.0 principles.


Why choose Agile Data Engine for Data Vault?
Up to 80% faster Data Vault implementation

Native support for all modern cloud database platforms

Compliance-ready metadata and audit trail
Designed by experts, built for enterprise scale
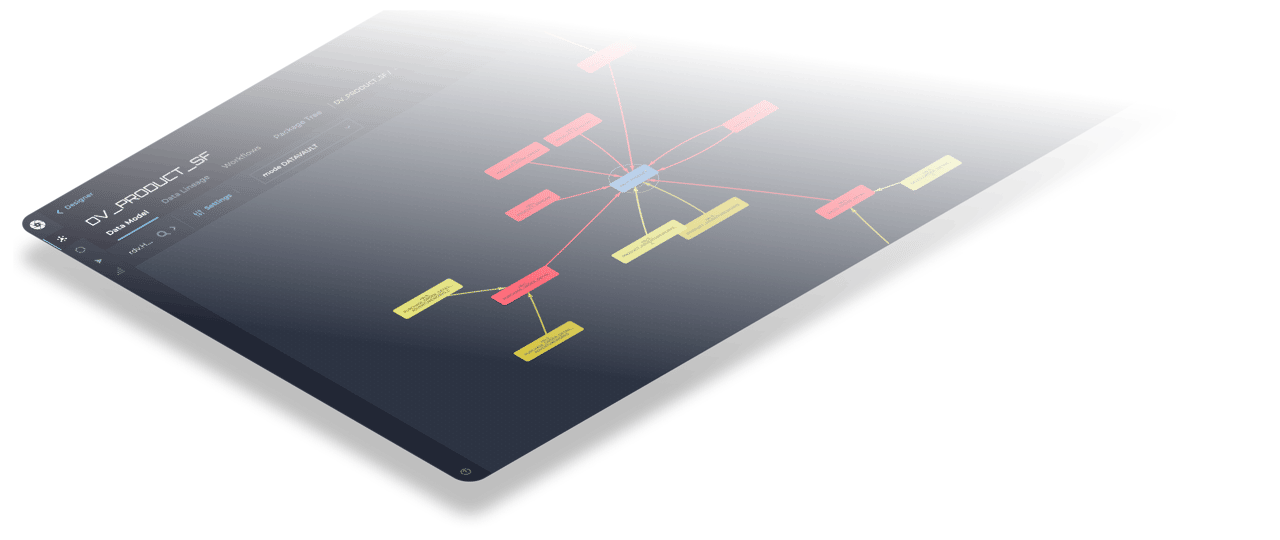
Become truly agile with Data Vault and Agile Data Engine
Accelerate data vault implementation by up to 80%
While powerful, Data Vault can be time-consuming to implement manually. ADE automates both data modeling and transformation logic—cutting development time by up to 80%. This allows your team to focus on delivering insights instead of building infrastructure.
Ideal for regulated industries
With a metadata-driven approach and full audit-trail capabilities, Data Vault together with Agile Data Engine is especially well-suited for regulated sectors like finance and healthcare. It helps you meet compliance requirements without compromising agility.
Built for scale and resilience
Agile Data Engine supports both horizontal scalability (more source integrations) and vertical scalability (large data volumes), helping you build a resilient, future-proof Data Vault architecture from the ground up.